
Flashear Firmware para PSAS CP400i (D3327-A1x)
Proyecto nuevo, servidor nuevo, discos nuevos, controladora nueva… Eso es algo que siempre hace ilusión poner en marcha. Lo que no hace tanta ilusión es que conectes la controladora por PCI y esta no funcione. Intentas tirar del fabricante, pero al final acabas del revés porque el éste no ha especificado con detalle como poder hacerlo o da por sentado que tienes un software para logarlo, el cual nunca has oído hablar y no tienes en tu poder. Este es un caso muy concreto que me ha ocurrido a mi, pero como sé perfectamente que dentro de 6 meses no me voy a acordar de la magia que hice en su día, así que aprovecho y lo comparto con vosotros por si os fuera de utilidad.
Cómo hacerlo
1. Descargar la utilidad sas3flash
En mi caso, lo hice desde esta web de Broadcom, y elegí el archivo SAS3FLASH_P15.
2. Descarga el controlador
Hazlo siempre desde la web oficial, para mitigar riesgos. En este caso, Fujitsu siempre te pide el número de serie para identificar el producto y descargar el controlador correcto.
https://support.ts.fujitsu.com/IndexDownload.asp
El controlador que utilicé yo contenía tres binarios, uno para firware, otro para la BIOS y otro para EFI.
3. Ejecuta la utilidad sas3flash
El comando a utilizar es el siguiente:
sas3flash -f lx4hbaG0.fw -b b83700.rom -b e180001.rom
Si es necesario, deberéis poner la ruta absoluta a los archivos .fw y .rom a la hora de ejecutar el comando.
4. Reinicia
Es obligatorio un reinicio inmediato de la máquina una vez se ha realizado correctamente el flasheo de la máquina.
Y ya estaría. Problema resuelto!
Reverse Proxy con NGINX + Docker
Hoy os traigo una serie de ficheros de configuración que estoy encantada de dejar como parte de este cajón de sastre. Se trata de una serie de archivos (Dockerfile, arhicvos .conf, etc) que quiero compartir con vosotros para crear en pocos pasos una imagen de NGINX que funcione como reverse proxy en local.
Mi Directorio
raiz |__>nginx | |__> conf.d | | |__> test.domain.com.conf | |__> ssl | | |__> tls.crt | | |__> tls.key | |___> nginx.conf |__> Dockerfile |__> docker.compose.yml
test.domain.com.conf
server {
listen 80;
listen 443 ssl http2;
listen [::]:80;
listen [::]:443 ssl http2;
server_name test.domain.com;
location / {
proxy_pass http://[IP]:[PORT];
}
error_page 404 /404.html;
location = /40x.html {
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
}
}nginx.conf
user www-data;
worker_processes auto;
pid /run/nginx.pid;
include /etc/nginx/modules-enabled/*.conf;
events {
worker_connections 768;
# multi_accept on;
}
http {
##
# Basic Settings
##
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 65;
types_hash_max_size 2048;
client_max_body_size 100M;
# server_tokens off;
# server_names_hash_bucket_size 64;
# server_name_in_redirect off;
include /etc/nginx/mime.types;
default_type application/octet-stream;
##
# SSL Settings
##
# ssl on;
ssl_protocols TLSv1 TLSv1.1 TLSv1.2; # Dropping SSLv3, ref: POODLE
ssl_prefer_server_ciphers on;
ssl_certificate /etc/nginx/ssl/tls.crt;
ssl_certificate_key /etc/nginx/ssl/tls.key;
##
# Logging Settings
##
access_log /var/log/nginx/access.log;
error_log /var/log/nginx/error.log;
##
# Gzip Settings
##
gzip on;
gzip_vary on;
gzip_proxied any;
gzip_comp_level 6;
gzip_buffers 16 8k;
gzip_http_version 1.1;
gzip_types text/plain text/css application/json application/javascript text/xml application/xml application/xml+rss text/javascript;
##
# Virtual Host Configs
##
include /etc/nginx/conf.d/*.conf;
include /etc/nginx/sites-enabled/*;
}
#mail {
# # See sample authentication script at:
# # http://wiki.nginx.org/ImapAuthenticateWithApachePhpScript
#
# # auth_http localhost/auth.php;
# # pop3_capabilities "TOP" "USER";
# # imap_capabilities "IMAP4rev1" "UIDPLUS";
#
# server {
# listen localhost:110;
# protocol pop3;
# proxy on;
# }
#
# server {
# listen localhost:143;
# protocol imap;
# proxy on;
# }
#}
Dockerfile
FROM nginx
COPY ./nginx/ /etc/nginx/docker-compose.yml
version: '3.4'
services:
nginx:
build:
context: .
dockerfile: Dockerfile
ports:
- 80:80
- 443:443Problema resuelto!
Programar encendido/apagado de VM en GCE
Google Cloud tiene una solución para cada necesidad. Entre las muchas cosas que se pueden hacer, os hoy dejo un mini tutorial de como hacer que las instancias de VM se enciendan y se paren según la programación que nosotros le definamos.
1. Requisitos previos
- Instancia/s de VM. Puedes ver aquí como crear una nueva instancia de VM.
- Etiquetas en esa instancia/s.
Para esta documentación, utilizaremos la etiqueta schedule:l-v.
2. Crear Cloud Functions con Cloud Pub/Sub
2.1. Crear la función de inicio.
- Ve a la página de Cloud Functions en GCP Console.
Ir a la página de Cloud Functions - Haz clic en Crear función.
- Configura el Nombre como startInstancePubSub.
- Deja el valor predeterminado en Memoria asignada.
- En Activador, selecciona Cloud Pub/Sub.
- En Tema, selecciona Create new topic…
- Aparecerá un cuadro de diálogo Nuevo tema pub/sub.
- En Nombre, ingresa start-instance-event.
- Haz clic en Crear para finalizar el cuadro de diálogo.
- En Entorno de ejecución, selecciona Node.js 10.
- Sobre el bloque de texto del código, selecciona la pestaña index.js.
- Reemplaza el código de inicio con lo siguiente:functions/scheduleinstance/index.js
const Compute = require('@google-cloud/compute');
const compute = new Compute();
exports.startInstancePubSub = async (event, context, callback) => {
try {
const payload = _validatePayload(
JSON.parse(Buffer.from(event.data, 'base64').toString())
);
const options = {filter: `labels.${payload.label}`};
const [vms] = await compute.getVMs(options);
await Promise.all(
vms.map(async instance => {
if (payload.zone === instance.zone.id) {
const [operation] = await compute
.zone(payload.zone)
.vm(instance.name)
.start();
// Operation pending
return operation.promise();
}
})
);
const message = `Successfully started instance(s)`;
console.log(message);
callback(null, message);
} catch (err) {
console.log(err);
callback(err);
}
};
const _validatePayload = payload => {
if (!payload.zone) {
throw new Error(`Attribute 'zone' missing from payload`);
} else if (!payload.label) {
throw new Error(`Attribute 'label' missing from payload`);
}
return payload;
}; 11. Sobre el bloque de texto del código, selecciona la pestaña package.json.
12. Reemplaza el código de inicio con lo siguiente:functions/scheduleinstance/package.json
{
"name": "cloud-functions-schedule-instance",
"version": "0.1.0",
"private": true,
"license": "Apache-2.0",
"author": "Google Inc.",
"repository": {
"type": "git",
"url": "https://github.com/GoogleCloudPlatform/nodejs-docs-samples.git"
},
"engines": {
"node": ">=8.0.0"
},
"scripts": {
"test": "mocha test/*.test.js --timeout=20000"
},
"devDependencies": {
"@google-cloud/nodejs-repo-tools": "^3.3.0",
"mocha": "^6.0.0",
"proxyquire": "^2.0.0",
"sinon": "^7.0.0"
},
"dependencies": {
"@google-cloud/compute": "^1.0.0"
}
}En Función a ejecutar, ingresa startInstancePubSub.
Haz clic en Crear.
2.2. Crear la función de detención
- Debes estar en la página de Cloud Functions en GCP Console.
- Haz clic en Crear función.
- Configura el Nombre como stopInstancePubSub.
- Deja el valor predeterminado en Memoria asignada.
- En Activador, selecciona Cloud Pub/Sub.
- En Tema, selecciona Create new topic…
- Aparecerá un cuadro de diálogo Nuevo tema pub/sub.
- En Nombre, ingresa stop-instance-event.
- Haz clic en Crear para finalizar el cuadro de diálogo.
- En Entorno de ejecución, selecciona Node.js 10.
- Sobre el bloque de texto del código, selecciona la pestaña index.js.
- Reemplaza el código de inicio con lo siguiente: functions/scheduleinstance/index.js
const Compute = require('@google-cloud/compute');
const compute = new Compute();
exports.stopInstancePubSub = async (event, context, callback) => {
try {
const payload = _validatePayload(
JSON.parse(Buffer.from(event.data, 'base64').toString())
);
const options = {filter: `labels.${payload.label}`};
const [vms] = await compute.getVMs(options);
await Promise.all(
vms.map(async instance => {
if (payload.zone === instance.zone.id) {
const [operation] = await compute
.zone(payload.zone)
.vm(instance.name)
.stop();
// Operation pending
return operation.promise();
} else {
return Promise.resolve();
}
})
);
const message = `Successfully stopped instance(s)`;
console.log(message);
callback(null, message);
} catch (err) {
console.log(err);
callback(err);
}
};
const _validatePayload = payload => {
if (!payload.zone) {
throw new Error(`Attribute 'zone' missing from payload`);
} else if (!payload.label) {
throw new Error(`Attribute 'label' missing from payload`);
}
return payload;
}; 11. Sobre el bloque de texto del código, selecciona la pestaña package.json.
12. Reemplaza el código de inicio con lo siguiente: functions/scheduleinstance/package.json
{
"name": "cloud-functions-schedule-instance",
"version": "0.1.0",
"private": true,
"license": "Apache-2.0",
"author": "Google Inc.",
"repository": {
"type": "git",
"url": "https://github.com/GoogleCloudPlatform/nodejs-docs-samples.git"
},
"engines": {
"node": ">=8.0.0"
},
"scripts": {
"test": "mocha test/*.test.js --timeout=20000"
},
"devDependencies": {
"@google-cloud/nodejs-repo-tools": "^3.3.0",
"mocha": "^6.0.0",
"proxyquire": "^2.0.0",
"sinon": "^7.0.0"
},
"dependencies": {
"@google-cloud/compute": "^1.0.0"
}
} 13. En Función a ejecutar, ingresa stopInstancePubSub.
14. Haz clic en Crear.
3. Verifica que tus funciones actúen correctamente
3.1. Detén la instancia
- Ve a la página de Cloud Functions en GCP Console.
Ir a la página de Cloud Functions - Haz clic en la función denominada stopInstancePubSub.
- Deberías ver algunas pestañas: General, Activador, Fuente, y Prueba. Haz clic en la pestaña Prueba.
- Para Evento de activación, ingresa lo siguiente:
1{"data":"eyJ6b25lIjoiZXVyb3BlLXdlc3QxLWIiLCJsYWJlbCI6InNjaGVkdWxlOmwtdiJ9"}- Esto es simplemente una string codificada en base64 que contiene la siguiente información: {«zone»:»europe-west1-b»,»label»:»schedule:l-v»}
- Si deseas codificar tu propia string, puedes usar cualquier herramienta de codificación en base64 en línea.
- Haz clic en el botón Probar la función.
- Cuando haya terminado de ejecutarse, deberías ver el texto Successfully stopped instance dev-app-01-instance debajo de Resultado. La ejecución puede tardar hasta 60 segundos en completarse.
- Ve a la página Instancias de VM en GCP Console.
Ir a la página Instancias de VM - Verifica que la instancia denominada dev-app-01 tenga un recuadro gris junto a su nombre. Esto indica que se detuvo. Puede tardar hasta 30 segundos en terminar de desactivarse.
- Si parece que no va a finalizar, prueba hacer clic en Actualizar en la parte superior de la página.
3.2. Inicia la instancia
- Ve a la página de Cloud Functions en GCP Console.
Ir a la página de Cloud Functions - Haz clic en la función denominada startInstancePubSub.
- Deberías ver algunas pestañas: General, Activador, Fuente, y Prueba. Haz clic en la pestaña Prueba.
- Para Evento de activación, ingresa lo siguiente:
1{"data":"eyJ6b25lIjoiZXVyb3BlLXdlc3QxLWIiLCJsYWJlbCI6InNjaGVkdWxlOmwtdiJ9"}- Nuevamente, esto es simplemente la string codificada en base64 para {«zone»:»europe-west1-b»,»label»:»schedule:l-v»}
- Haz clic en el botón Probar la función.
- Cuando haya terminado de ejecutarse, deberías ver el texto Successfully started instance workday-instance debajo de Resultado.
- Ve a la página Instancias de VM en GCP Console.
Ir a la página Instancias de VM - Verifica que la instancia denominada dev-app-01 tenga una marca de verificación verde junto a su nombre. Esto indica que se está ejecutando. Puede tardar hasta 30 segundos en terminar de iniciarse.
4. Configurar los trabajos de Cloud Scheduler para llamar a Cloud Pub/Sub
Nota: La programación se especifica con el formato cron para UNIX. Ejemplos: Cada minuto «* * * * *»; cada 3 horas «0 */3 * * *»; todos los lunes a las 9:00 «0 9 * * 1». Más información
4.1. Crea el trabajo de inicio
- Ve a la página de Cloud Scheduler en GCP Console.
Ir a la página de Cloud Scheduler - Haz clic en Crear trabajo.
- Configura el Nombre como startup-l-v-instance.
- En Frecuencia, ingresa 0 6 * * 1-5.
- En Zona horaria, selecciona el país y la zona horaria que desees. En este ejemplo, usaremos United States y Los Angeles.
- En Destino, selecciona Pub/Sub.
- En Tema, ingresa start-instance-event.
- En Carga útil, ingresa lo siguiente:
1{"zone":"europe-west1-b","label":"schedule:l-v"} - Haz clic en Crear.
4.2. Crea el trabajo de detención.
- Debes estar en la página de Cloud Functions en GCP Console.
- Haz clic en Crear trabajo.
- Configura el Nombre como shutdown-l-v-instance.
- En Frecuencia, ingresa 0 21 * * 1-5.
- En Zona horaria, selecciona el país y la zona horaria que desees. En este ejemplo, usaremos United States y Los Angeles.
- En Destino, selecciona Pub/Sub.
- En Tema, ingresa stop-instance-event.
- En Carga útil, ingresa lo siguiente:
1{"zone":"europe-west1-b","label":"schedule:l-v"} - Haz clic en Crear.
5. Verifica que los trabajos funcionen
5.1. Detén la instancia
- Ve a la página de Cloud Scheduler en GCP Console.
Ir a la página de Cloud Scheduler - En el trabajo denominado shutdown-l-v-instance, haz clic en el botón Ejecutar ahora en el extremo derecho de la página.
- Ve a la página Instancias de VM en GCP Console.
Ir a la página Instancias de VM - Verifica que la instancia denominada app-dev-01-instance tenga un recuadro gris junto a su nombre. Esto indica que se detuvo. Puede tomar hasta 30 segundos para que termine de desactivarse.
5.2. Inicia la instancia
- Ve a la página de Cloud Scheduler en GCP Console.
Ir a la página de Cloud Scheduler - En el trabajo denominado startup-l-v-instance, haz clic en el botón Ejecutar ahora en el extremo derecho de la página.
- Ve a la página Instancias de VM en GCP Console.
Ir a la página Instancias de VM - Verifica que la instancia denominada dev-app-01-instance tenga una marca de verificación verde junto a su nombre. Esto indica que se está ejecutando. Puede tardar hasta 30 segundos para que termine de iniciarse.
Problema resuelto!
Subir imágenes al Container Registry de GCP
No es nada complicado, pero es importante que hay tres maneras diferentes de subir una imágen al repositorio de GCP.
Dockerfile
1. Crea o descarga un fichero Dockerfile
Con tu editor de texto favorito, o bien descargado de Dockerhub, sitúa el fichero Dockerfile en la carpeta que quieras.
2. Compila la imagen con Dockerfile
Cloud Build te permite compilar una imagen de Docker mediante un Dockerfile. No necesitas un archivo de configuración de compilación diferente.
Ejecuta el comando siguiente desde el directorio que contiene quickstart.sh y Dockerfile, en el que [PROJECT_ID] es tu ID del proyecto de GCP:
gcloud builds submit --tag gcr.io/[PROJECT_ID]/[IMAGE_NAME] .Ejemplo:
gcloud builds submit --tag gcr.io/tg-gcp-project/rabbitmq .YAML
- Crea un Dockerfile con la información que necesites.
- En el mismo directorio que contiene Dockerfile, crea un archivo llamado cloudbuild.yaml con los contenidos siguientes. Este archivo es tu archivo de configuración de compilación. A la hora de la compilación, Cloud Build reemplaza $PROJECT_ID con tu ID del proyecto de manera automática.
steps:
name: 'gcr.io/cloud-builders/docker'
args: [ 'build', '-t', 'gcr.io/$PROJECT_ID/rabbitmq2', '.' ]
images: 'gcr.io/$PROJECT_ID/rabbitmq2'3. Comienza la compilación con la ejecución del comando siguiente:1 gcloud builds submit --config cloudbuild.yaml .
Nota
No omitas el «.» al final del comando anterior. Con “.”, se especifica que el código fuente se encuentra en el directorio de trabajo actual al momento de la compilación.
Imagen Local
Etiqueta la imagen local con el nombre del registro mediante el siguiente comando:
docker tag [SOURCE_IMAGE] [HOSTNAME]/[PROJECT-ID]/[IMAGE]Envía la imagen etiquetada a Container Registry con el siguiente comando:
docker push [HOSTNAME]/[PROJECT-ID]/[IMAGE]docker push [HOSTNAME]/[PROJECT-ID]/[IMAGE]:[TAG]
Problema resuelto!
Alertas Útiles en Google Cloud Platform
Intro
Me gustaría empezar esta entrada con un síntoma que he sufrido bastante en las empresas donde he tenido el placer de trabajar:
El Día a Día Me Come (DDMC)
Fransu Rondán
Se podría aplicar en muchos aspectos, tanto personales como profesionales. Pero hoy me gustaría hacer hincapié en esa gran aliada, apenas utilizada en las infraestructuras de sistemas: La monitorización.
Da igual como se llame la herramienta: Stackdriver, Zabbix, Nagios… Es una inversión de tiempo que se recupera a corto plazo. Lo importante es tenerla, configurarla y hacerle caso.
Ventajas
- Detección e identificación temprana de problemas.
- Ejecución de acciones preventivas.
- Alertas y notificación de las incidencias.
- Generación de informes de rendimiento y seguridad.
- Capacidad para optimizar recursos.
¿Qué monitorizar?
En esta entrada no vamos a centrar en los indicadores del rendimiento (KPI) de VM y de contenedores de Kubernetes, en concreto la RAM y CPU, puesto que Google Cloud Platform es una plataforma demasiado flexible para detallarlo todo.
Memoria
Instancias de máquina virtual
| Nombre del recurso | VM Instance |
| Etiqueta del recurso en la consulta | gce_instance |
| Nombre de la métrica: | Memory utilization |
| Descripción de la métrica: | Tamaño en bytes de memoria usada obtenida utilizando el agente de stackdriver. |
| Etiqueta de la métrica en la consulta: | agent.googleapis.com/memory/percent_used |
| Tipos de memoria disponibles para la monitorización: | buffered cached free slab1 used |
| Nombre del recurso | VM Instance |
| Etiqueta del recurso en la consulta | gce_instance |
| Nombre de la métrica: | VM Memory Used |
| Descripción de la métrica: | Memoria actual usada en la VM. Solo disponible para las VM de la familia e2. |
| Etiqueta de la métrica en la consulta: | compute.googleapis.com/instance/memory/balloon/ram_used |
| Tipos de memoria disponibles para la monitorización: | buffered cached free slab1 used |
Kubernetes
| Nombre del recurso | GKE Container |
| Etiqueta del recurso en la consulta | k8s_container |
| Nombre de la métrica: | Memory Usage |
| Descripción de la métrica: | Uso de memoria en bytes |
| Etiqueta de la métrica en la consulta: | kubernetes.io/container/memory/used_bytes |
| Tipos de memoria disponibles para la monitorización: | evitable: Fácilmente reclamada por el kernel non-evitable: No fácilmente reclamada por el kernel |
CPU
INSTANCIAS DE MÁQUINA VIRTUAL
| Nombre del recurso | VM Instance |
| Etiqueta del recurso en la consulta | gce_instance |
| Nombre de la métrica: | CPU utilization |
| Descripción de la métrica: | Porcentaje de CPU usado obtenido utilizando el agente de stackdriver. |
| Etiqueta de la métrica en la consulta: | agent.googleapis.com/cpu/utilization |
| Estados de CPU disponibles para la monitorización: | idle: Cuando no lo está usando ningún programa. interrupt: Señales enviadas por dispositivos externos a la CPU para detener las actividades actuales. nice: Tiempo dedicado a ejecutar procesos con buen valor positivo. softirq: Cuando se ejecuta un controlador de interrupciones o una función diferible. steal: Tiempo que una CPU virtual espera una CPU real mientras el hipervisor está dando servicio a otro procesador. system: CPU utilizada por el sistema user: CPU utilizada por el usuario wait: cantidad de tiempo que una tarea tiene que esperar para acceder a los recursos de la CPU |
Hay muchos tipos de memoria, y todos deberían ser monitorizados. Sin embargo, considero que lo más fácil sería monitorizar que siempre tengamos un porcentaje libre de idle. No sabremos que tipo de memoria exactamente está dando el problema, pero detectaremos que algo está ocurriendo y podremos tomar medidas.
Podríamos configurar alertas, por ejemplo, que detectaran cuando la memoria idle disponible es inferior al 30% durante 1h.
| Nombre del recurso | VM Instance |
| Etiqueta del recurso en la consulta | gce_instance |
| Nombre de la métrica: | CPU utilization |
| Descripción de la métrica: | Utilización fraccionada de la CPU asignada. Los valores son típicamente números entre 0.0 y 1.0. Los gráficos muestran los valores como un porcentaje entre 0% y 100% |
| Etiqueta de la métrica en la consulta: | compute.googleapis.com/instance/cpu/utilization |
| Valores de CPU disponibles para la monitorización: | cpu/utilization |
Kubernetes
Debido a la forma de funcionar y a la lógica de Kubernetes, GCP no nos proporciona para los contenedores un parámetro utilization como pasaba con las máquinas virtuales. En su lugar nos ofrece los siguientes parámetros:
- kubernetes.io/container/cpu/core_usage_time
- kubernetes.io/container/cpu/limit_cores
- kubernetes.io/container/cpu/limit_utilization
- kubernetes.io/container/cpu/request_cores
- kubernetes.io/container/cpu/request_utilization
Sin embargo, si queremos saber el uso de CPU, los clusters de GKE al final son maquinas virtuales en el entorno de GCE. Para evitarnos sustos, siempre es recomendable tener el cluster monitorizado como una máquina más.
Discos / Volumenes
Instancias de máquina virtual
| Nombre del recurso | VM Instance |
| Etiqueta del recurso en la consulta | gce_instance |
| Nombre de la métrica: | Disk usage |
| Descripción de la métrica: | Disco usado en bytes obtenido utilizando el agente de stackdriver. Solo para VM Linux. |
| Etiqueta de la métrica en la consulta: | agent.googleapis.com/disk/bytes_used |
| Tipo de uso: | free reserved used |
| Nombre del recurso | VM Instance |
| Etiqueta del recurso en la consulta | gce_instance |
| Nombre de la métrica: | Disk usage in Bytes |
| Descripción de la métrica: | Disco usado en bytes. |
| Etiqueta de la métrica en la consulta: | compute.googleapis.com/guest/disk/bytes_used |
| Valores de CPU disponibles para la monitorización: | cpu/utilization |
Filtros:
- resource.namespace_name
- resource.container_name
- metric.memory_type:
- Values:
evictable: It is memory that can be easily reclaimed by the kernelnon-evictable. , Is memory that can not be easily reclamied by the kernel.
- Values:
Chuleta – Pipeline para Jenkins
En mi día a día, trabajo bastante con Jenkins. Nada del otro universo, una maquinita local, corriendo jenkins, vinculada con gcloud y cuenta de servicio. Tengo toda la potencia del bash de unix y la versatilidad de Jenkins como CI.
pipeline {
agent any
environment {
STAGE_NAME_BB = ""
SRC_PATH="[local_src_path]" #Ruta donde deberá encontrarse el proyecto GIT que debe ser compilado.
SCRIPTS_PATH="[scripts_path]" #Ruta donde se almacena el script para eliminar las imágenes antiguas
NAMESPACE="[k8_namespace]"
K8_OBJ="[workload_type]/[workload_name]"
CONTAINER="[container_name]"
IMAGE="[src_image]"
}
stages {
stage("Compile Code"){
steps {
notifyBuild("STARTED")
script{
STAGE_NAME_BB = "Compile Code"
}
echo "Building..."
sh "Comandos a ejecutar para la compilación del código"
}
}
stage("Unit Testing"){
steps {
script{
STAGE_NAME_BB = "Unit testing"
}
echo "En este apartado puedes configurar los test para tu código"
}
}
stage("Image Push & Tag into Container Registry"){
steps {
script{
STAGE_NAME_BB = "Image Push & Tag into Container Registry"
}
echo "# Subir la imagen al container registry..."
sh "cd ${SRC_PATH} && mvn jib:build -Djib.to.image=${IMAGE}:${BUILD_NUMBER}"
echo "# Agregar la etiqueta latest a la imagen que acabamos de subir"
sh "cd ${SRC_PATH} && gcloud container images add-tag ${IMAGE}:${BUILD_NUMBER} ${IMAGE}:latest --quiet"
}
}
stage("Deploying Image into its Kubernetes Container"){
steps {
script{
STAGE_NAME_BB = "Deploying Image into its Kubernetes Container"
}
echo "# Connecting to dev cluster"
sh "gcloud container clusters get-credentials [cluster-name] --zone [cluster-zone] --project [project-name]"
echo "# Configurar la nueva imagen como la ultima imagen de la carga de trabajo especificada"
sh "cd ${SRC_PATH} && kubectl set image ${K8_OBJ} ${CONTAINER}=${IMAGE}:${BUILD_NUMBER} --record -n ${NAMESPACE}"
}
}
stage("Delete Container Registry Old Images"){
steps {
script{
STAGE_NAME_BB = "Delete Container Registry Old Images"
}
echo "# Deleting old images"
echo "# Para mas detalles de este script, podéis consultar esta entrada"
sh "cd ${SCRIPTS_PATH} && ./delete_old_images.sh ${IMAGE}"
}
}
}
post {
success {
notifyBuild("SUCCESSFUL")
}
failure {
notifyBuild("FAILED ${STAGE_NAME_BB}")
}
}
}
def notifyBuild(String buildStatus = 'STARTED') {
// build status of null means successful
buildStatus = buildStatus ?: 'SUCCESSFUL'
// Default values
def colorName = 'RED'
def colorCode = '#FF0000'
def subject = "${buildStatus}: Job '${env.JOB_NAME} [${env.BUILD_NUMBER}]'"
def summary = "${subject} (${env.BUILD_URL})"
// Override default values based on build status
if (buildStatus == 'STARTED'){
color = 'YELLOW'
colorCode = '#FFFF00'
summary = "${subject} (${env.BUILD_URL})"
}
else if (buildStatus == 'SUCCESSFUL') {
color = 'GREEN'
colorCode = '#00FF00'
}
}
Problema resuelto!
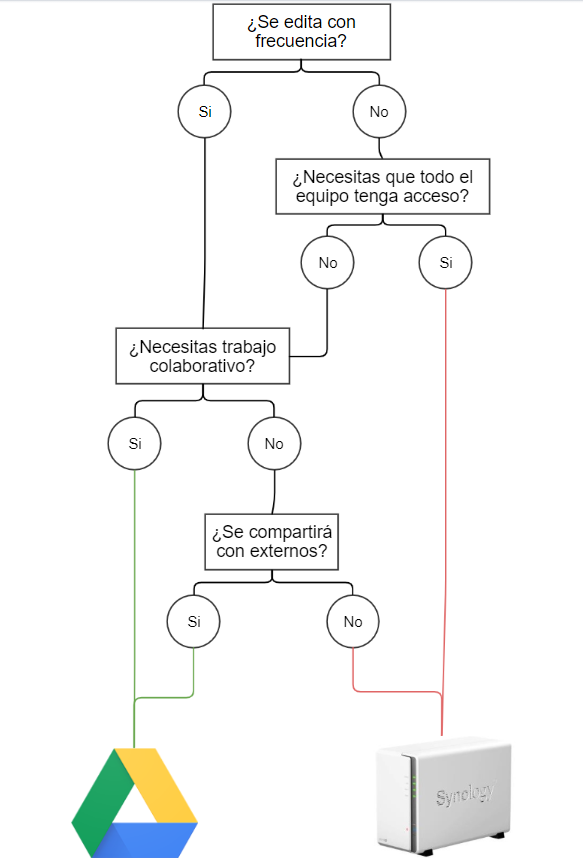
Buenas prácticas: ¿Almacenaje cloud o NAS?
Estás a punto de guardar un documento pero no estás seguro donde debería estar guardado. ¿Lo guardas en el cloud o lo guardas en la NAS?
Tanto Cloud (OneDrive, Google Cloud) como la NAS son dos servicios de almacenamiento de archivos. Ambos son medios son complementarios entre sí dentro del lugar de trabajo, pero hay ciertos casos en los que es mejor usar uno u otro. Depende de la situación.
Tradicionalmente, los mejores casos para usar Cloud son cuando:
- Necesitas compartir un archivo/carpeta con externos a la organización.
- Es un archivo “vivo”. Se edita y modifica con frecuencia.
- Necesitas realizar trabajo colaborativo simultáneo sobre el archivo con otro compañer@.
- Es un archivo que solo lo vas a usar tu.
Los mejores casos para usar la NAS son cuando:
- No necesitas trabajo colaborativo
- Es un archivo “estático”, que sufre pocos o ningún cambio a lo largo del tiempo.
- Tiene que estar en un repositorio común para todos los miembros del equipo.
Problema resuelto!
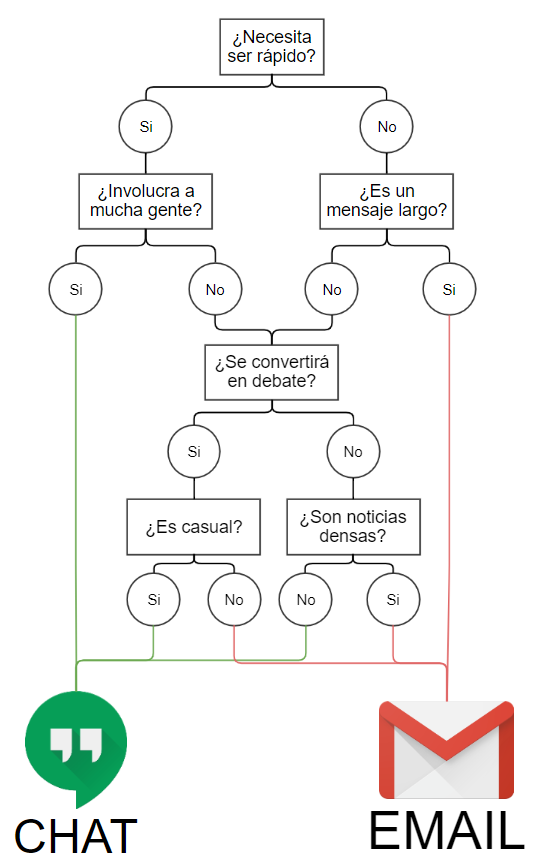
Buenas prácticas: ¿Email o chat?
Estás a punto de enviar un mensaje para actualizar a su compañera de trabajo sobre su último proyecto. ¿Escribes un correo electrónico o le escribes a Hangouts?
Tradicionalmente, los mejores casos para usar el correo electrónico son cuando:
- El contenido es demasiado largo para enviar mensajes.
- El mensaje es información pesada.
- El mensaje requiere formalidad.
- Es la primera vez que contactas a alguien
Los mejores casos para usar el chat son cuando:
- Debe ser rápido y oportuno
- El mensaje es conciso.
- Es un diálogo con múltiples personas
- La discusión debe ser más informal.
Árbol de decisión
Por qué
Oportunidad
El correo electrónico es asíncrono, lo que significa que un correo electrónico que envía a su compañero de trabajo no es en tiempo real como
lo es la mensajería. Esta es una diferencia clave para el razonamiento detrás del uso de uno versus el otro. La mensajería es instantánea, por lo
que sería más rápido que el correo electrónico cuando se trata de enviar información a alguien.
Según un estudio sobre el uso de mensajes por parte de IBM, la razón principal por la cual las personas eligen usar mensajes en cualquier otro
medio en un momento dado es porque permite una «respuesta rápida» y «respuestas rápidas y cortas».
Longitud
Originalmente, el chat estaba destinado a ser breve, mientras que el correo electrónico podía manejar mensajes más voluminosos y con mucho
contenido. Esto es una ventaja cuando se trata de mensajes porque significa que puedes ser más informal y rápido con lo que tienes que decir.
Pedir a los compañeros de trabajo que almuercen contigo se comunica mejor a través de mensajes, mientras que dar a alguien detalles largos
sobre un informe sería mejor por correo electrónico.
Diálogo
Tanto el correo electrónico como la mensajería se usan para el diálogo, pero el correo electrónico de ida y vuelta es muy diferente a la
mensajería. El chat es mejor si la conversación continuará durante más de unas pocas oraciones. El chat también refleja el cara a cara
más que el correo electrónico, lo que también es una razón para usar uno sobre el otro cuando se trata de largas conversaciones en línea.
Según un estudio de The Radicati Group, «el uso comercial de mensajería instantánea está creciendo a un ritmo mucho más rápido que el uso
de mensajería instantánea por parte de los consumidores». El estudio analiza todo tipo de mensajes, incluidos mensajes instantáneos,
mensajería instantánea pública, mensajería instantánea empresarial y mensajería móvil. El crecimiento de la mensajería muestra que el correo
electrónico no es la única forma de enviar un mensaje en el trabajo.
Problema resuelto!
Chuleta de YAML para Kubernetes en GCP
Nunca viene mal una chuleta cuando se trabaja con Kubernetes. En este caso, es una chuleta especial para el entono de GKE en la plataforma de GCP. En este caso, son el tipo de cargas de trabajo, servicios, etc. que más suelo usar en mi día a día. Espero que os sean de utilidad.
Deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: name-deployment
namespace: dev
labels:
app: app-name
spec:
replicas: 1
selector:
matchLabels:
app: app-name
template:
metadata:
labels:
app: app-name
spec:
containers:
- name: container-name
image: container-image:tag
ports:
- containerPort: 1234
envFrom:
- configMapRef:
name: configmap-name
- secretRef:
name: secret-name
volumeMounts:
- name: name-vol
mountPath: /unix/source/route/map
volumes:
- name: name-vol
persistentVolumeClaim:
claimName: name-pvc
StatefulSet
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: name-statefulset
namespace: dev
labels:
app: app-name
spec:
serviceName: app-service-name"
replicas: 1
selector:
matchLabels:
app: app-name
template:
metadata:
labels:
app: app-name
spec:
containers:
- name: container-name
image: container-image:tag
ports:
- containerPort: 1234
name: port-name
resources:
limits:
memory: "2000Mi"
requests:
memory: "300Mi"
envFrom:
- configMapRef:
name: configmap-name
- secretRef:
name: secret-name
volumeMounts:
- name: name-vol
mountPath: /unix/source/route/map
volumes:
- name: name-vol
persistentVolumeClaim:
claimName: name-pvcCronjob
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: name-cronjob
namespace: dev
spec:
schedule: "01 0 * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: container-name
image: container-image:tag
args:
- /bin/sh
- -c
- sh /scripts/script.sh
restartPolicy: Never
PVC
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: name-pvc
namespace: dev
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 25Gi
ConfigMap
apiVersion: v1 kind: ConfigMap metadata: name: genportal-integration-config namespace: dev data: #Comments VAR_NAME: "value"
Secrets
apiVersion: v1 kind: Secret metadata: name: name-secret namespace: dev type: Opaque data: VAR_NAME: "password_in_base_64"
Service
apiVersion: v1
kind: Service
metadata:
name: name-service
labels:
app: app-name
namespace: dev
spec:
ports:
- port: 1234
protocol: TCP
targetPort: 1234
selector:
app: app-name
sessionAffinity: None
type: LoadBalancer / ClusterIP / NodePort
status:
loadBalancer: {}
Tipos de servicio en función de su comportamiento:
- ClusterIP: expone el servicio en una IP interna del clúster. Elegir este valor hace que el Servicio solo sea accesible desde dentro del clúster. Este es el ServiceType predeterminado.
- NodePort: expone el servicio en la IP de cada nodo en un puerto estático (el NodePort). Se crea automáticamente un servicio ClusterIP, al que se enruta el servicio NodePort. Podrá ponerse en contacto con el servicio NodePort, desde fuera del clúster, solicitando <NodeIP>: <NodePort>.
- LoadBalancer: expone el servicio de forma externa mediante el equilibrador de carga de un proveedor de nube. Los servicios NodePort y ClusterIP, a los que se enruta el equilibrador de carga externo, se crean automáticamente.
Problema resuelto!
Chuleta de PSQL
Aunque te hayas pegado a menudo con una base de datos postgresql, normalmente, se tocan de uvas a peras. Es difícil acordarse de todo, y por ello, hoy os dejo mi chuleta personal cuando no me acuerdo de algo.
Ficheros de configuración
/var/lib/postgresql/11/main' # use data in another directory
/etc/postgresql/11/main/postgresql.conf' #default conf file
/etc/postgresql/11/main/pg_hba.conf' # host-based authentication file
Conectarse desde cliente psql
Para hacer login en la BD postgres, utilizaremos la siguiente sintaxis:
psql -h [HOST] -U [user] [BD]Ejemplo:
psql -h localhost -U user_name db_name
Visualizar ROLES
\duResultado:
Lista de roles
Nombre de rol | Atributos | Miembro de
-----------------+------------------------------------------------+------------
postgres | Superusuario, Crear rol, Crear BD, Replicación | {}
xxxxxxxxx | Superusuario | {}
yyyyyyyyyyy | | {}Crear un GRUPO
CREATE ROLE nombre [ [ WITH ] opción [ ... ] ]Donde opción puede ser:
SUPERUSER | NOSUPERUSER
| CREATEDB | NOCREATEDB
| CREATEROLE | NOCREATEROLE
| CREATEUSER | NOCREATEUSER
| INHERIT | NOINHERIT
| LOGIN | NOLOGIN
| REPLICATION | NOREPLICATION
| CONNECTION LIMIT límite_conexiones
| [ ENCRYPTED | UNENCRYPTED ] PASSWORD 'contraseña'
| VALID UNTIL 'fecha_hora'
| IN ROLE nombre_de_rol [, ...]
| IN GROUP nombre_de_rol [, ...]
| ROLE nombre_de_rol [, ...]
| ADMIN nombre_de_rol [, ...]
| USER nombre_de_rol [, ...]
| SYSID uidEjemplo:
CREATE GROUP dev WITH LOGIN NOCREATEDB NOSUPERUSER NOCREATEROLE;Dar permisos de conexión sobre una BD
GRANT { { CREATE | CONNECT | TEMPORARY | TEMP } [,...] | ALL [ PRIVILEGES ] }
ON DATABASE database_name [, ...]
TO { [ GROUP ] role_name | PUBLIC } [, ...] [ WITH GRANT OPTION ]Para más info de GRANT sobre postgres, visitar:
Postgres GRANT
Ejemplo:
GRANT CONNECT ON DATABASE tellmegen TO dev;Mostrar todos los SCHEMA disponibles
select schema_name from information_schema.schemata;
Resultado:
schema_name
--------------------
isisaudit
isiscommand
isissecurity
isissessionlogger
pg_toast
pg_temp_1
pg_toast_temp_1
pg_catalog
information_schema
publicDar permisos de SELECT, INSERT… sobre SCHEMA
GRANT { { SELECT | INSERT | UPDATE | DELETE | TRUNCATE | REFERENCES | TRIGGER }
[,...] | ALL [ PRIVILEGES ] }
ON { [ TABLE ] table_name [, ...]
| ALL TABLES IN SCHEMA schema_name [, ...] }
TO { [ GROUP ] role_name | PUBLIC } [, ...] [ WITH GRANT OPTION ]Ejemplo:1
GRANT SELECT, INSERT, UPDATE, DELETE ON ALL TABLES IN SCHEMA public TO dev;Crear usuario y agregarlo a grupo
Utilizaremos la misma sintaxis que para crear un grupo. Ejemplo:
CREATE ROLE user_name WITH LOGIN NOCREATEDB NOSUPERUSER NOCREATEROLE CONNECTION LIMIT 1 PASSWORD 'password' IN GROUP dev;Es interesante establecer CONNECTION LIMIT 1, para evitar suplantación de identidad del usuario
Cambiar de grupo al usuario
Eliminar usuario del grupo:
REVOKE user_name FROM group_name;Modificar el fichero de conexión pg_hba.conf
Para permitir el acceso del usuario, hay que modificar el fichero pg_hba.conf. Esta configuración no funciona para usuarios, así que para permitir el acceso, habrá que añadir a cada usuario de manera individual.
/var/lib/pgsql/9.3/data/pg_hba.confo o para postgres11:
/etc/postgresql/11/main/pg_hba.confLa sintaxis del fichero debe de llevar alguna de las siguientes formas:
# local DATABASE USER METHOD [OPTIONS]
# host DATABASE USER ADDRESS METHOD [OPTIONS]
# hostssl DATABASE USER ADDRESS METHOD [OPTIONS]
# hostnossl DATABASE USER ADDRESS METHOD [OPTIONS]Ejemplo para login local:
local database_name user_name peerEjemplo para login remoto / pgadmin:
host database_name user_name ip/32 trustReiniciar siempre el servicio de postgres para aplicar cambios:
service postgresql-9.3.service restartProblema resuelto!